


In the fast-evolving world of IoT, managing the relentless flow of data from MQTT topics into a scalable IoT pipeline is no small feat. This is the story of how I built one such pipeline using AWS Kinesis, Lambda, Glue Catalog, and S3, transforming raw IoT data into queryable insights with Athena. Along the way, I faced unexpected challenges — like taming unorganized data streams, optimizing file partitioning, and uncovering the magic of an MSCK query. Each hurdle revealed valuable lessons and a few surprises that kept me on my toes. Let’s dive in if you’re ready to explore how these tools come together to handle IoT data at scale! ⚡
The Data Flow Dilemma 🤨
Draft AWS IoT Pipeline 📡
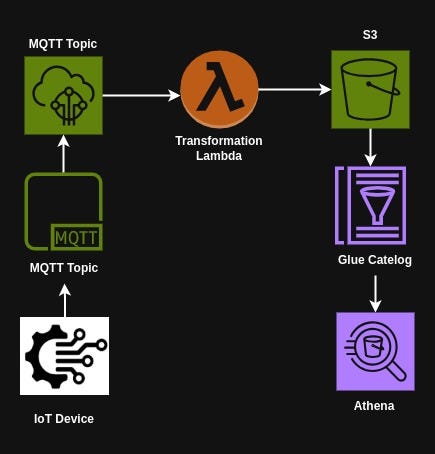
IoT Rule: Create an IoT rule that triggers a Lambda function whenever data is published to the MQTT topic. This ensures that every message is captured as soon as it is sent.
Lambda Function: Develop a Python-based AWS Lambda function to transform the incoming data and write it to an S3 bucket. The function would handle formatting, adding metadata, and organizing the data into appropriate folders.
Glue Catalog: Use AWS Glue to create a schema for the data. This registers the data’s structure, making it accessible for querying.
Athena Queries: Finally, leverage AWS Athena to query the data in S3. Athena’s serverless nature makes it an ideal choice for running SQL queries directly on the S3 data.

It sounded straightforward, but as I delved deeper, I quickly realized the potential pitfalls. IoT devices generate massive amounts of data at a relentless pace. Writing this data directly to S3 without proper organization or accumulation would lead to a flood of small, inefficient files. Querying such data would be slow and costly.
Realization 🧠
But as soon as I started thinking about the scale of data IoT generates — 2 messages every 3 seconds — I realized something wasn’t quite right. Writing all this data straight into S3 could result in a mess of tiny, unorganized files, causing major inefficiencies down the line — a classic “data dump.”
Implementation — Building the Pipeline 🏗️
The Lightbulb Moment: Enter AWS Kinesis 💡
I needed a solution that could accumulate and organize the incoming flood of data, and that’s when I decided to bring AWS Kinesis into the picture. This service not only helps buffer and batch data but also provides a mechanism to store it in an orderly fashion before pushing it into S3.
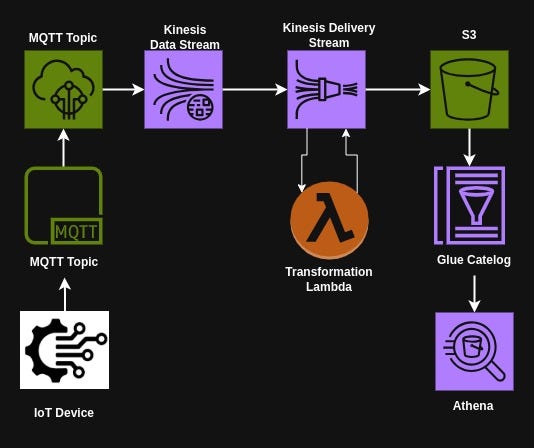
Hence the new dataflow:
Step 1: Define IoT Rules — The Gateway to Data Streams 🚪
The first step was to capture the IoT data at its source. AWS IoT Rules act as an intelligent gateway, listening to MQTT topics and forwarding the data to a Kinesis Data Stream in real-time. This setup ensures that all incoming messages are captured reliably, preventing data loss. The flexibility of IoT Rules allows the filtering and routing of specific data streams based on business logic.
Step 2: Route Data with Precision — Streamlined to Kinesis Delivery 🚛
Once the data reaches the Kinesis Data Stream, it must be efficiently routed for further processing. This is where the Kinesis Delivery Stream comes in. The Data Stream acts as a high-throughput buffer, ensuring that large volumes of IoT messages can be ingested without overwhelming downstream systems. The Delivery Stream then takes over, ensuring a smooth transition of raw data into the transformation and storage layers.
Step 3: Transform Data on the Fly — Lambda to the Rescue 🦸♂️
Raw IoT data often requires some level of transformation before storage. AWS Lambda integrates seamlessly with Kinesis Delivery Stream, enabling real-time processing on each incoming batch. In this step, I configured a Lambda function to cleanse, enrich, and format the data, ensuring it met the structure required for downstream querying. This transformation layer helps standardize data while keeping it lightweight and optimized for analytics.
Step 4: Accumulating and Organizing Data — Deliver to S3 🏞️
The transformed data flows directly into an S3 bucket, providing a secure, scalable, and cost-effective storage solution. This marks the beginning of the data lake, where historical and real-time data can coexist for future analytics.
However, the next challenge was how to accumulate the data before sending it to S3. I had a few questions that needed answers:
What should be the accumulation time?
How big should each accumulated file be?
What partitioning strategy should I use for S3?
After analyzing the message size and frequency, I came up with these solutions:
✅ Accumulate data over 15 minutes
✅ Set the maximum file size to 200 MB
✅ Use a date-based partitioning strategy to organize files in S3:
📁 iot_data/year=YYYY/month=MM/day=dd/hour=HH
Step 5: Visualization: Making Data Accessible — AWS Glue Catalog & AWS Athena 🔎
To enable seamless querying, I leveraged AWS Glue Catalog to structure the raw S3 data into a table. This metadata-driven approach laid the foundation for powerful analytics. Since the client wanted the ability to run queries, I turned to AWS Athena, which allows SQL-like queries on S3 data without managing infrastructure. However, before diving into Athena, I first had to explore the data, define its schema, and register it in Glue Catalog — ensuring Athena could recognize and efficiently query the data on demand.
This pipeline established a structured and scalable approach to handling high-velocity IoT data, ensuring that raw messages were efficiently processed, stored, and prepared for analysis. With data now flowing seamlessly through Kinesis, S3, Glue Catalog, and Athena, the foundation was set for deeper exploration and optimization — yet, there were still a few surprises along the way. 🤔
🚀 Post-Deployment Validation
✅ Everything Looks Good… Or Does It?
After deploying the pipeline, I checked the logs of the Kinesis Delivery Stream — everything seemed fine. I queried the data using Athena and was able to retrieve the expected results.
But then, after some new data was written to S3, things took an unexpected turn. 😨
My pipeline ran successfully, and new data showed up in S3. I ran a query in Athena to check the new data and… ❌ Error.
I couldn’t fetch the latest data. Moreover, the new data wasn’t showing up in the Glue Catalog either. 🤔

🔍 The Mystery of Missing Data
After hours of Googling and reading StackOverflow posts, I learned a crucial lesson: AWS Glue doesn’t automatically detect new data partitions unless I do either of the following:
✅ Run Glue Crawler to add new partitions to the Glue Catalog, or
✅ Run a special command called MSCK REPAIR.
MSCK REPAIR TABLE is a Hive command that can be used with AWS Athena (or other compatible engines like Presto or Hive) to update the metadata of a partitioned table in the Glue Data Catalog. It’s also much cheaper than running an AWS Crawler, making it a better choice in many cases.
🎄 The Christmas Surprise: Data from the Future
Just when I thought the storm had passed, something even stranger happened. After taking a break for the holidays, I returned to find that my pipeline had written data with a date value one year in the future. 😳 Yes, you read that right: data was timestamped with a future date!

After a good laugh and some head-scratching, I found the culprit: a small but critical mistake in my partitioning strategy.
🕵️ The Difference Between “YYYY” and “yyyy”
In my partitioning strategy, I had used YYYY instead of yyyy. The difference? 🤯
📌 YYYY refers to the week year—it’s based on the ISO week numbering system, which sometimes results in a year that’s different from the calendar year.
📌 yyyy refers to the calendar year, which follows the Gregorian calendar, and that’s what I needed for consistent file naming.
Once I fixed this, everything started working as expected. 🎯
🚀 Conclusion: Building a Scalable AWS IoT Data Pipeline
Building an IoT data pipeline isn’t just about moving data — it’s about designing a system that can handle high-velocity streams efficiently while keeping data organized, accessible, and queryable. Through this journey, I tackled key challenges and uncovered some unexpected lessons. Here are my biggest takeaways:
1️⃣ Data organization is key — Writing raw IoT data directly to S3 creates chaos. Using AWS Kinesis helped buffer and batch data before storage, ensuring a structured approach.
2️⃣ MSCK REPAIR to the rescue — If you don’t explicitly update your Glue Catalog, Athena won’t recognize new partitions in S3. Running MSCK REPAIR is a must for keeping queries up-to-date.
3️⃣ Partitioning strategy matters — Choosing the right strategy (like year=yyyy/month=MM/day=dd/hour=HH) improves query performance and storage efficiency.
4️⃣ Small mistakes can have big consequences — A tiny detail like using YYYY instead of yyyy can completely mess up your data organization—leading to an unexpected (and hilarious) holiday surprise.
5️⃣ AWS services make scaling easy — With Kinesis, Lambda, Glue, and Athena, I built a pipeline that seamlessly ingests, transforms, and queries IoT data, delivering valuable insights to the client.
In the end, this project reinforced an important lesson: Every challenge is a chance to learn something new — sometimes, in ways you’d never expect! 🚀